I wiped out my old and boring installation and replaced it with the shiny and new Clear Linux desktop 38700. It’s like a breath of fresh air for my PC. And guess what? The NVIDIA driver 530.41 (thanks to @marioroy ) works like a charm too (Just tweak the display settings and watch the instant magic happen!). My PC is now CLEARly the best in the neighbourhood.
And don’t get me started on the speed of CL development. They are on fire! They keep adding new features and improvements every day. I can’t keep up with them. Thank you Clear Linux Development team for making my PC dreams come true.
(Used Bing to write this to get @Businux to reply fast!)
@Indy, I am curious as to how your system performs mandelbrot-python auto-zooming demonstration. Do not bother if you run Python via another means than Miniconda or Anaconda. The Miniconda is how I run Python on Clear Linux.
Note: The CUDA and OpenCL demonstrations require double-precision HW on the GPU. This means Intel graphics will not work due to lacking double-precision support. However, the CPU demonstrations should work.
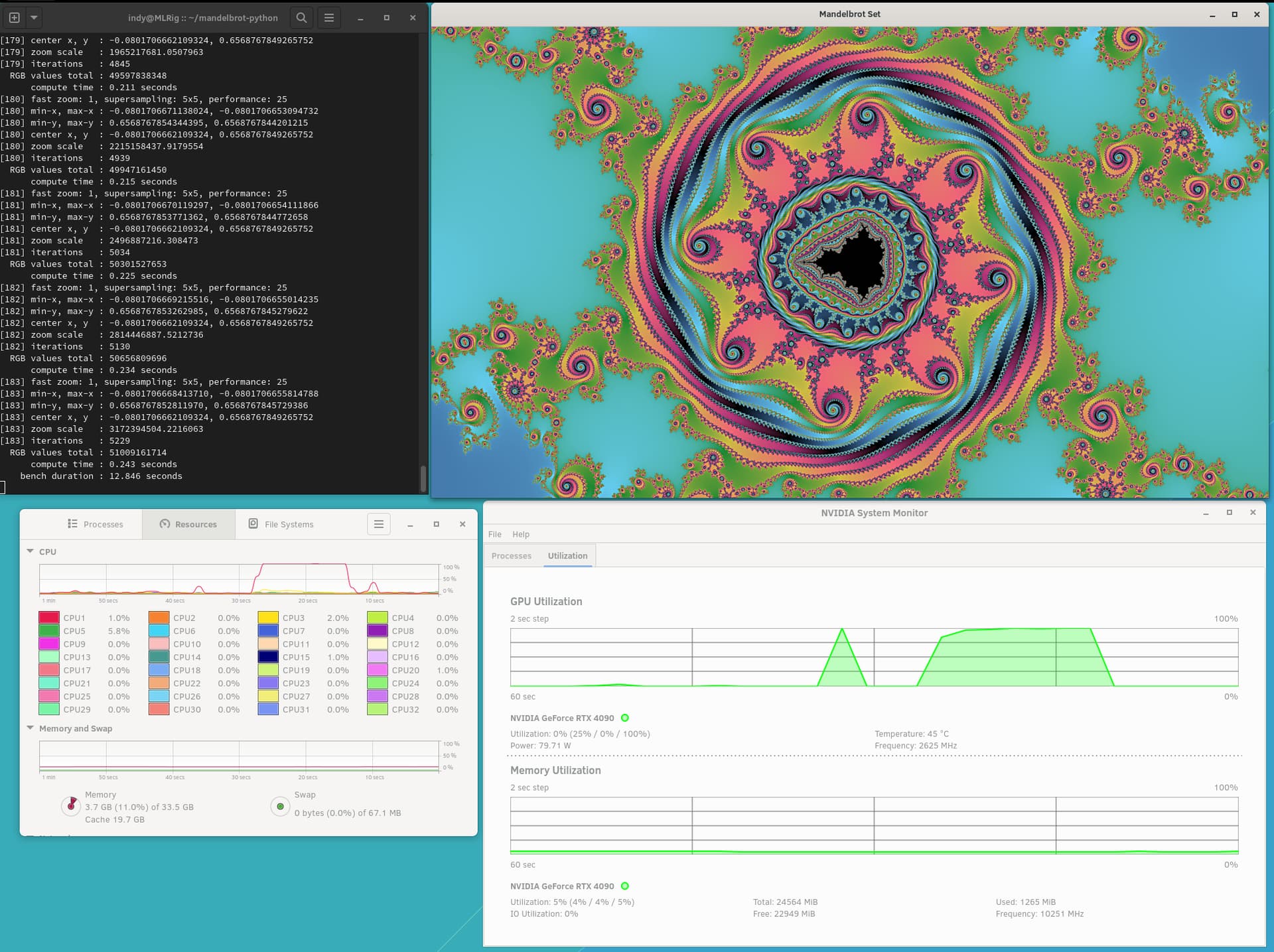
Press the letter “m” or “h” to render with 3x3 or 5x5 super-sampling, respectively.
Then, press the letter “c” to render ~ 183 levels. There are several auto zooms { z, x, c, v, b, g, and t } to various locations. Color schemes (press F1 … F7).
Clear Linux is a lot of fun for me, personally. This platform is where I learned Numba, OpenCL, and CUDA using Python. Miniconda is a blessing for folks using Python and not worry about messing with the OS-level Python.
I created the NVIDIA on Clear Linux repo for ease of use of installing the NVIDIA driver and CUDA Toolkit. The Python repo is my sandbox for learning Python; pycuda, pyopencl, Numba, and pygame. Numba is awesome.
curious why the OS level python is inferior to the miniconda one… the data I saw on phoronix some time ago is that the clear linux python is at least… quite a bit faster
Installing llvmlite, a dependency for Numba, is the reason using Miniconda. It’s a pain getting llvmlite to build on CL against llvm11.
Recent Numpy 1.22 or newer emits warnings due to some library or dependency built with fast-math enabled. Unfortunately, another reason using Miniconda and installed Numpy 1.21.5.
The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
Finally, it’s feasible getting the modules needed in Miniconda and not worry about building modules that have many dependencies.
Please know that I tried the OS-level Python first.
That is amazing performance for the Intel processor. It is similar to running on an AMD Threadripper 3970X box using 32 “real” cores (factoring out the logical threads). Wow!
The RTX 4090 double-precision performance is about 4 times that of the RTX 3070 GPU. Thank you for sharing.
Ditto. Thank you, @arjan. I tried the OS-level Python, but the frustrations took me over, getting various Python modules to build.
Numba is amazing, taking Python code to C-level performance via directives (akin to OpenMP). I tried all the variations including my own parallelization using the Python multiprocessing module; queues and sockets.
mandel_queue.py - Run parallel using a queue for IPC
mandel_stream.py - Run parallel using a socket for IPC
mandel_parfor.py - Run parallel using Numba's parfor loop
mandel_ocl.py - Run on the CPU or GPU using PyOpenCL
mandel_cuda.py - Run on the GPU using PyCUDA
mandel_kernel.py - Run on the GPU using cuda.jit
Regarding 2160p missing, you can edit app.ini and add a section. Scroll near the bottom of the file. Or you can pass --width N and --height N arguments instead of --config app.ini.
Which display settings did you tweak? I had met to ask earlier.
Again, thank you for sharing. The RTX 4090 (48.5 secs) is a beast. It is 3.8 times faster than the RTX 3070 (184.0 secs) computing the 1080p (u) 7x7 super-sampling (c) demonstration.