Imagine the thrill of running a large language model (LLM) in the comfort of your home, and that too on a ten-year-old Mac Pro! The idea seems improbable. To spice things up, I’m planning on using Clear Linux for this project, an OS known for its performance optimization and security features . This would breathe new life into my old Mac. Here’s the twist though - I’m a complete newbie in the worlds of Linux and Machine Learning. The excitement and complexity of the challenge is pretty daunting, but also incredibly exhilarating. I’m here to learn and collaborate, and I’m eager to dive deep into this venture with the wisdom and support of this fantastic community. Let’s turn this vision into a reality, together!
As part of this endeavor, I have my eyes set on setting up a project from GitHub that I believe will be instrumental in this journey. It’s called Dalai, a self-hosted service for GPT-3-like models (link: GitHub - cocktailpeanut/dalai: The simplest way to run LLaMA on your local machine). This exciting tool promises to give individuals the power to host their own language models, bringing cutting-edge AI tech into the realm of personal computing. But as you can imagine, for someone new to Linux and ML, figuring out how to install and run this on an old Mac Pro using Clear Linux is going to be quite the puzzle. I’ll need all the help and guidance I can get from you, the knowledgeable minds in this community. Let’s make this old Mac Pro come alive with AI!
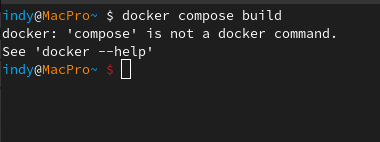
First and foremost, I’ve encountered my initial roadblock in setting up Docker Compose in Clear Linux. As per my research and a forum post I found https://community.clearlinux.org/t/no-docker-compose/8781, there seems to be an issue with the ‘compose’ binary missing in Clear Linux. Docker Compose is crucial for my project, as it’s the tool that will help me define and run multiple-container Docker applications, necessary for running the Dalai project.
Thanks for the mention ^.^ It’s interesting to see people’s usage of tools like ChatGPT to navigate things like Linux. Hopefully you can figure everything else out too! Apologies that my prior post didn’t include all of those little details - it was intended as a feedback post of “Hey, you guys should fix this” - rather than a tutorial on how to set it up. There is indeed docker-compose available on Clear Linux (notice the hyphen), but it is a previous major version (version 1) available as a separate binary and written in python. Whereas docker compose is version 2, written in Go, and used as a plugin of docker rather than a separate binary.
Thankyou @Gorian for the post. chatGPT is very useful for a linux novice like me. It almost feel like a tutor I have access to anytime.
The model downloaded via the docker container appear to be corrupt. I am trying to figure out how to copy the llama model I have into the model directory at the moment! I had to use sudo to run docker commands. Container appear to have created a model directory in the cloned github project folder with root ownership. So, I can’t use Nautilus to drag and drop files. LOL
I am learning the basics of linux file ownership and the chown command.
I wanted to share an update on the exciting project I’ve been working on - running large language models on a 10-year old Mac Pro 5,1 using Clear Linux!
After some challenges with the Dalai project, I managed to successfully run the LLAMA project, available here. Notably, I was able to run the 7B model at a good speed, making the 30B quantized model almost usable. Even the gigantic 65B quantized model was able to run! I believe this serves as a compelling proof of concept that such models can indeed be run on a decade-old Mac Pro 5,1.
With this significant progress, I am now moving onto the next phase of the project: setting up a Gradio web interface. This will allow members of our community to access a running model.
As I embark on this next challenge, I welcome any tips, insights, or advice from the community.
It’s interesting ‘System Monitor’ not correctly showing the amount of RAM used. When I ran C++ executable with root privileges ( ) RAM usage was properly displayed, around 46GB.